Research Proposal: New Inference Paradigms for ML at the Edge
Jinming Ren 
Edge AI, RISC-V, FPGA, CFU, Quantization, Spiking Neural Networks, Neuromorphic Computing, ANN-to-SNN, Compute-in-Memory, Real-time Detection, Event Cameras, Co-design.
Motivation
Over the past decade, cloud-based training and inference pipelines face growing issues of high latency, bandwidth bottlenecks, data privacy issues [1] and escalating training energy cost [2], etc. Edge GPUs partially alleviate these issues but, on the one hand, remain too general-purpose, lacking flexibility for custom numeric precisions, memory hierarchy and data movement [3]. On the other hand, different applications stress different aspects:
- Autonomous systems, UAVs, Controlled nuclear fusion: Demand sub-millisecond latency for control stability and decision safety [4], [5], [6].
- Medical and IoT devices: Prioritize data privacy and local analytics to meet regulatory and ethical standards [1].
Recent evidence [7] shows FPGA-based accelerators can outperform GPUs in both energy efficiency and deterministic latency when tuned for application-specific workloads. Therefore, FPGA-based hardware–software co-design emerges as a promising solution for low-power, low-latency edge computing tailored to specific application needs.
Problem Statement & Research Questions
Problem. Edge AI is constrained by end-to-end latency, energy per inference, and privacy. General-purpose accelerators lack support for application-specific numerics and event-driven workloads. SNNs promise ultra-low-power inference but lack portable toolchains (IR/quantization) and competitive accuracy at low time-steps.
How far can RISC-V + FPGA co-design push latency/energy for real-time perception while preserving accuracy?
Can SNNs with internal complexity (multi-timescale, adaptive thresholds) match ANN accuracy at few-time-step inference on FPGA?
What portable SNN IR + quantization API enables “write once, target multiple back-ends” without accuracy regressions?
Which dataflows (streaming vs memory-centric) minimize data motion for attention/convolution bottlenecks at the edge?
Project Objectives & Expected Contributions
An open source, reproducible full-stack edge ML system (models \(\to\) compiler \(\to\) RTL \(\to\) bitstream) that surpasses the ANN GPU-edge baseline on \(\ge 2\) of {latency, energy per inference, accuracy} for a selected application scenario.
A portable SNN IR + quantization API for spike dynamics, demonstrated on FPGA.
Evidence that internal complexity can reduce depth/width and time-steps while maintaining accuracy on edge tasks.
An open benchmark harness with NeuroBench-style reporting for fair cross-hardware comparison.
There are two variables to choose though:
- Application scenario: Suits edge computing and extremely low latency (possibly video stream processing / controlled nuclear fusion).
- Target network structure: Possibly accelerating RT-DETR [8] or YOLO, or directly optimize existing Spiking Neural Networks (SNNs).
Methodology
To achieve the project objectives, the proposed research will follow a three-stage methodology: The warm-up phase establishes an ANN baseline and a RISC-V-coupled FPGA accelerator with deterministic low-latency dataflows. The mid-term phase investigates brain-inspired computing, especially SNNs, focusing on improving accuracy, enhancing LIF model (increasing “internal complexity” [9], [10]), sparse computation, quantization / pruning models and establishing SNN standard APIs. The long-term phase explores emergent intelligence by investigating hypercomputation beyond Turing limits. The details are as shown in the following sections.
Warm-up: Von Neumann path (RISC-V + FPGA, ANN first)
This phase has been planned as my graduation project, with the aim to pushing the limits of von Neumann architecture (RISC-V) in edge computing by accelerating and optimizing existing ANNs. Take target network RT-DETR [8] as an example, the steps are as follows:
Quantization & pruning for edge: We adopt sub-8-bit quantization (INT8 \(\to\) INT4/INT2 if accuracy allows) and structured sparsity to minimize off-chip transfers. We will report accuracy-latency-energy trade-offs under identical datasets and input resolutions.
RISC-V-based accelerator with CFU Playground: As a undergraduate warm-up project, we will imitate the design flow in [11] as shown in Figure fig-warm-up. We will implement a VexRiscv + Custom function unit (CFU) design within the open-source CFU Playground framework [12] shown in Figure fig-cfu-playground. The difficulties are to design customized extended instructions in RISC-V for computational-intensive operators (e.g., depthwise/pointwise convolution, \(QK^T\), low-bit GEMM), write the corresponding RTL for the hardware.
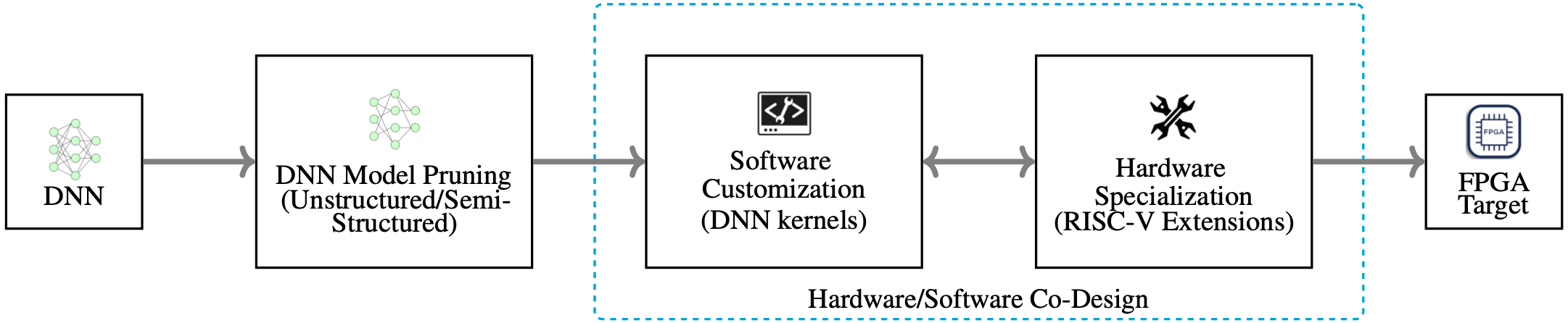
Figure 1: Warm-up phase design flow (adapted from [11]) Full-stack design and DSE: As a learning experience, we will reinvent the wheel by designing the entire accelerator in
Chiselfrom scratch and open-sourcing it on Github. Then, we also explore a large multi-dimensional design space exploration (DSE) using automated methods (such as heuristic or evolutionary algorithms) to identify optimal configurations balancing accuracy, energy, and latency. Finally, we will use Arty A7-100T FPGA as the hardware platform for real measurements.

Mid-term: Brain-Inspired path (SNN on FPGA, portable toolchain)
This phase is planned to be my potential PhD research topic. We will explore Brain-Inspired Computing (BIC) in computer vision tasks with a particular focus on EdgeSNNs (parameters \(< 100\text{ M}\) [1]) and In-Memory Computing (CIM).

SNNs have shown promise for ultra-low-power, event-driven inference at the edge. SNNs model neurons with explicit membrane dynamics (LIF model as shown in Figure fig-lif-model). Unlike conventional ANNs, SNNs process information in the temporal domain using binary spikes (event-driven coding), this is particularly suitable for SpikeCV cameras [13], which in my view are the next-generation vision sensors for edge applications such as autonomous driving.
Previous work on SNNs in autonomous driving includes Spiking-YOLO [14], EMS-YOLO [15], etc. However, the performance is still not good in general compared to ANN [16]. ECS-LIF in [16] suggests high-performance spiking detectors are possible with ANN-level matched accuracy and ultra-low energy costs. However, one still need to carefully select hardware architectures. For video classification, research is even more nascent [13]. Early attempts include spiking recurrent networks (processing up to 300 time steps of video frames), or hybrid ANN-SNN approaches for action recognition [13], SpikeVideoTransformer [17], SpikeYOLO [18]. However, there is no SNN equivalent yet for many popular video models (e.g. no published spiking variant of SlowFast or DETR detection-transformer as of 2025).
Since the research steps are not as clear as the warm-up phase, I list some potential research directions in parallel below:
Explore SNN design / training method: There are two routes to get optimized SNNs: ANN2SNN conversion [1], [8], or direct-training SNNs. We will explore both routes to find the best-performing SNNs for our target application. We will also investigate advanced training techniques such as surrogate gradients, temporal backpropagation, and biologically inspired learning rules to improve SNN performance.
Develop unified SNN toolchain: SNNs lack standard APIs and SNN-specific IRs (analogous to ONNX [1], [19]) for quantization strategies tailored to spike dynamics [19]. We prototype a minimal graph-level SNN IR (ops, neuron nodes, timing semantics) plus a quantization API (e.g., \(\text{INT8} \times \text{INT2}\) spike ops, ternary spikes, per-layer time-step budgets) to decouple front-end training from back-end compilers, following the direction of NIR and recent co-design work that targets FPGA-friendly spike arithmetic. This addresses today’s fragmentation across neuromorphic stacks and enables “write once, target FPGA/Loihi/MCU.” [20]
Further explore SNN internal complexity: A recent study [9], [10] by Network model with internal complexity bridges artificial intelligence and neuroscience shows a pivotal shift in thinking: Instead of simply growing neural networks by adding more layers or parameters (“external complexity”), we can embed richer dynamics inside each neuron or module — a paradigm the authors term “small model with internal complexity.”
Long-term: Emergent Intelligence
This phase is my long-term aspiration toward artificial general intelligence (AGI). This stage will explore the theoretical and practical computational boundary and brand-new distributed computing paradigms inspired by the human brain under the guidance of recent theoretical investigations into emergence in artificial systems, such as Berti et al. (2025) [21] who survey emergent abilities in LLMs and identify conditions like scaling, criticality and compression that contribute to spontaneous capability gains. Continuing the exploration of internal complexity in #sec-mid-term, there are two major directions: Turing-complete machine and hypercomputation beyond Turing limits.
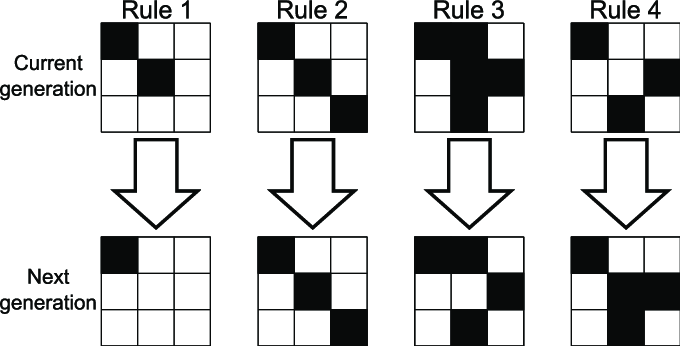

- Decentralized, event-driven architectures: We will first explore turing-complete hardware and software systems that mimic the highly-distributed, asynchronous nature and learning-while-inferencing feature of the brain. Turing-equivalent cellular automata such as CGOL [25] (Figure fig-cgol), Langton’s ant, Particle Life already demonstrate how simple local rules can give rise to complex, emergent patterns (Figure fig-gosper-glider-gun, Figure fig-pl1, Figure fig-pl2). While using the CGOL itself as a practical “computer” is inefficient, it serves as a proof-of-concept that emergence can arise from simple components. The challenge is discovering the right set of rules (i.e., internal complexity) or learning algorithms that yield robust emergent intelligence, not just (external) complexity for its own sake [26]. Then turn out to nature (the hardware) to find out if there is a machine under our control that performs this set of rules intrinsically.


- Hypercomputation beyond Turing limits: Human brain might be exploiting computational principles beyond the scope of traditional Turing machines. Penrose and others (like Stuart Hameroff) have hypothesized that quantum effects in neural microstructures (e.g. microtubules) could enable the brain to do things standard computers cannot [27]. Achieving AI with brain-like cognition might then require tapping into quantum computing [28], ONNs [29], Organoid Intelligence (OI) [30], [31] and beyond.