CPU 原理速成
This chapter is under construction!
Change of Mind
- 对于有时钟的电路, 我们应该想象成: 电路的状态只在时钟的上升沿「瞬间」变化. 时钟的上升沿发生时电路做了两件事情:
- 前一个时钟周期的计算结果该锁存的 锁存到寄存器 中.
- 下一个时钟周期的结果瞬间计算出来并 放在线上 (他们目前还不能被 CPU “看到”).
CPU 是如何成为现在这个样子的?
The following is a critical path towards understanding CPU. You can’t drop any of them. 以下是理解 CPU 的必经之路.
分而治之, 穷举 + 控制信号
分而治之: 一条指令的执行可以拆分为这几个阶段 (phase):
IF (Instruction Fetch): 取指.
ID (Instruction Decode): 译码.
- ID 后面有些地方 [1] 后面还细分了 Evaluate Address 和 Fetch Operands.
EX (Execute): 执行.
ME (Memory Access): 访存.
WB (Write Back): 写回.
每个 phase 都可以有固定的输入和输出, 所以每个 phase 都对应一个 (或多个) 电路模块.
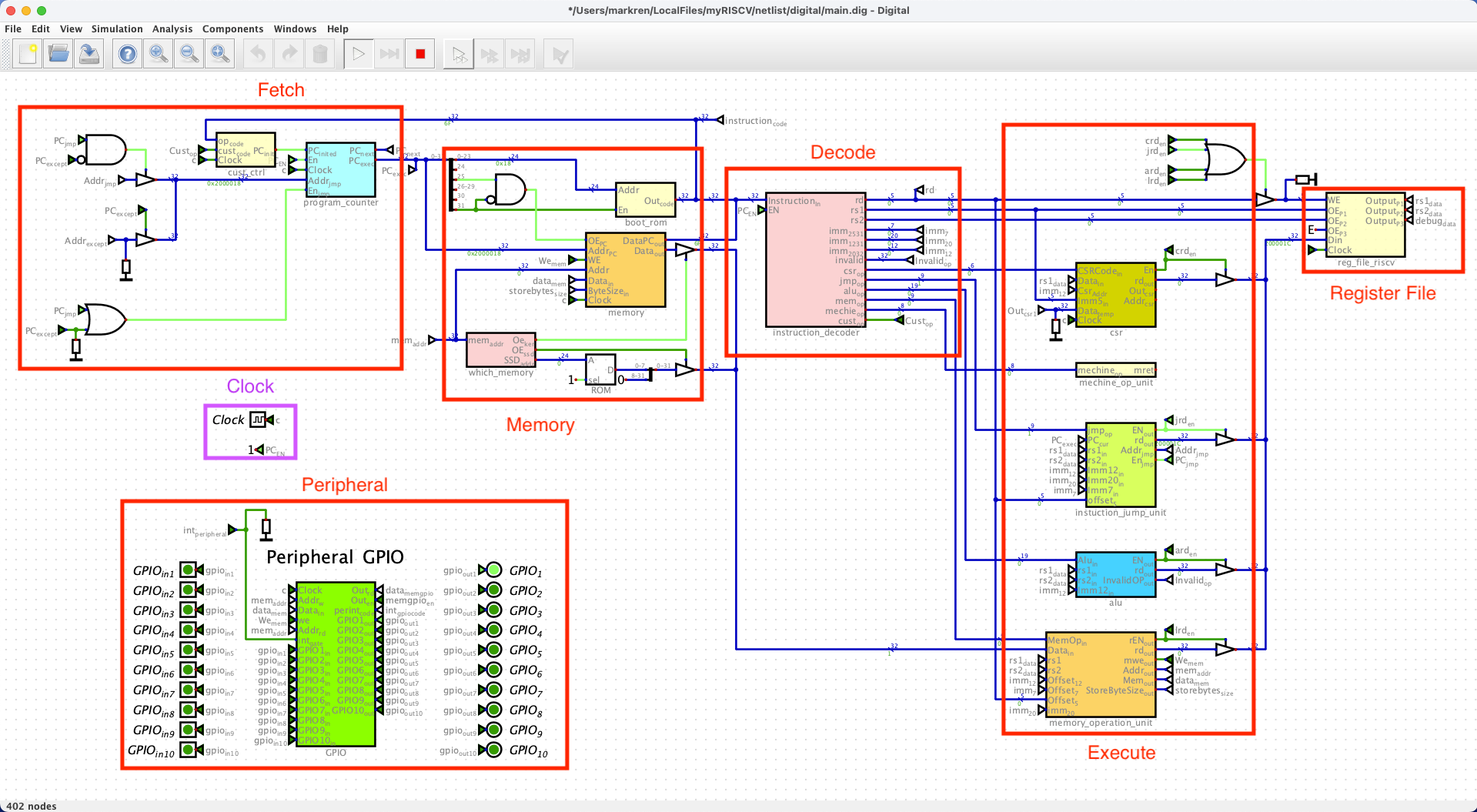
这个 phase 的 CPU 可以通过我的 my-riscv 项目 可视化地理解
Arithmetic 运算: 读取某些寄存器的值, 运算之后再放回某个寄存器中 (不能读写内存)
Load/Store 访存: 唯一能访问内存的指令. 将某个寄存器的值写到某个内存地址 (或者反过来)
Control 控制流: 跳转 (其实就是改变 pc 寄存器的值 (还有顺带改变一下 ra 寄存器))
穷举 + 控制信号 思想: 每个电路模块用硬件写死, 以 ALU 单元 (Execute 的其中一个模块) 为例, 所有可能的输出都计算出来 (说是计算, 其实就是一个数字电路通了而已, 电路通了结果自然就在输出端口显示出来了, 没有「计算」的过程. 比如 ALU), 只不过在输出之前用控制信号来决定哪个计算结果才是我们要的 (一般控制信号都由 Decoder 产生, 因为 Decoder 的作用就是 (根据 Opcode) 将一条指令解读为如何控制各个模块应该输出什么结果).
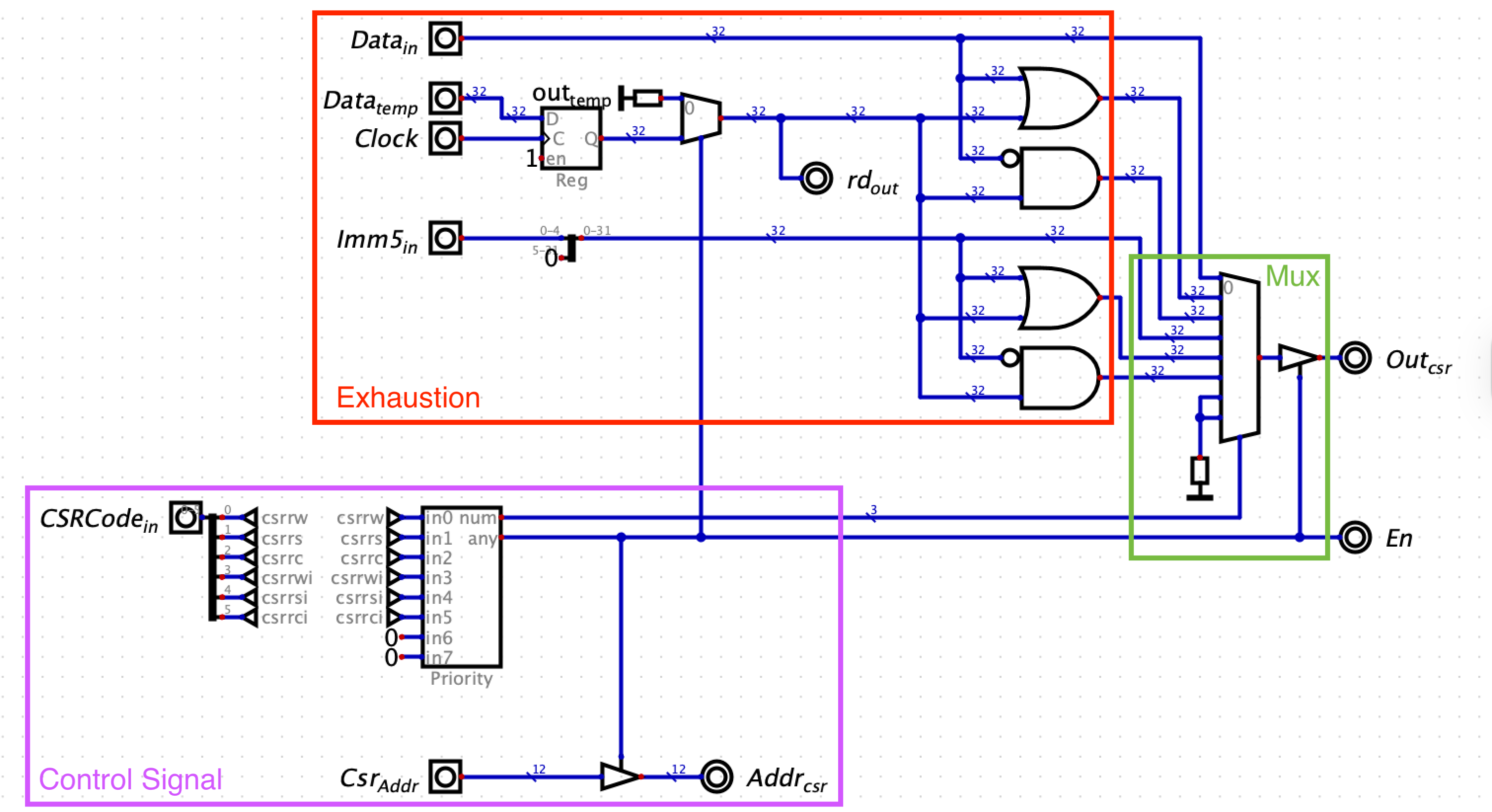
穷举 + 控制信号 思想在 ALU 内部的体现 一条指令的执行的那几个 phase 可以设计成:
Single-Cycle: 在一个时钟周期内完成所有 phases. 由于电路有延迟, 所有 phase 的电路很长, 要求时钟频率不能很高.
Multi-Cycle: 每个时钟周期只执行一个 phase.
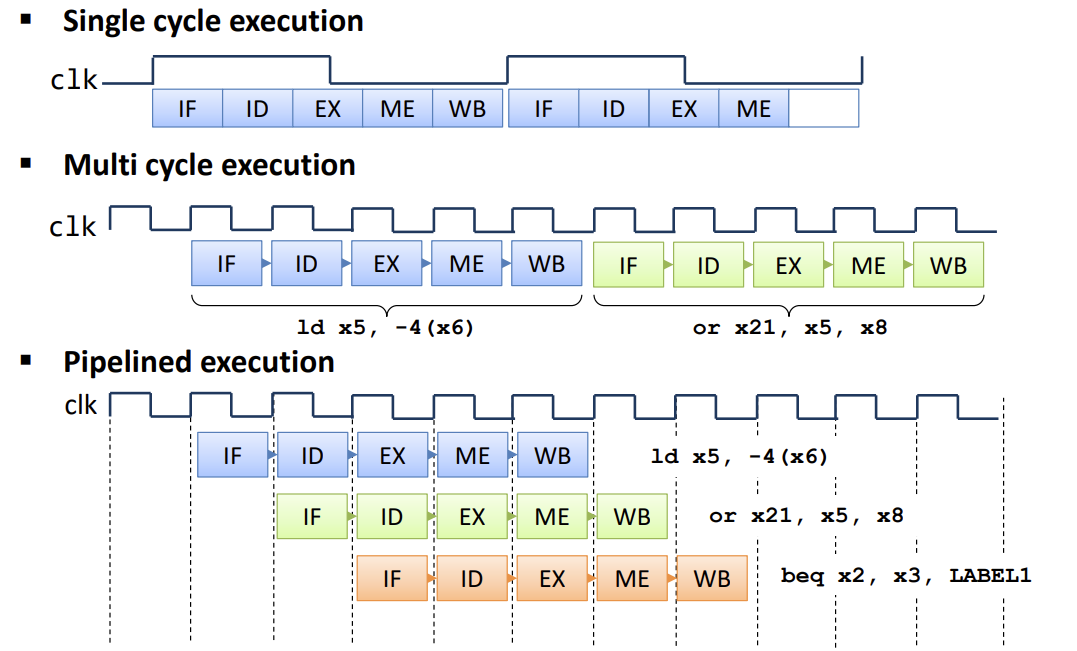
Figure 1: 为了提升指令执行效率引入了 Pipeline [2]
这样的 CPU: simple, general, 但是 not efficient!
流水线
Pipeline 流水线: 见 Figure fig-single-mult-pipelined.
在每两个 phase 之间插入一些受始终控制的寄存器:
- IF-ID 之间: 当前指令, PC 值 (
jal要用) - ID-EX 之间: 指令类型, rs1, rs2, rd, imm.
- IF-ID 之间: 当前指令, PC 值 (
第三阶段
总线: ARM 公司研发了很多总线, 他们的集合称为 AMBA (Advanced Microcontroller Bus Architecture). 包括: APB, AHB, AXI. Xilinx 公司很多异构的 FPGA都需要引入 AXI 总线.
AXI 特点:
- 面向存储: 指主、从机在读到数据之后一般都会将这些数据先放在某种储存里面.
- 突发总线:
Cache 缓存
Cache 的存在就是由于 DRAM 的读写太慢了, 如果 RAM 读写非常快的话就不需要 Cache 了.
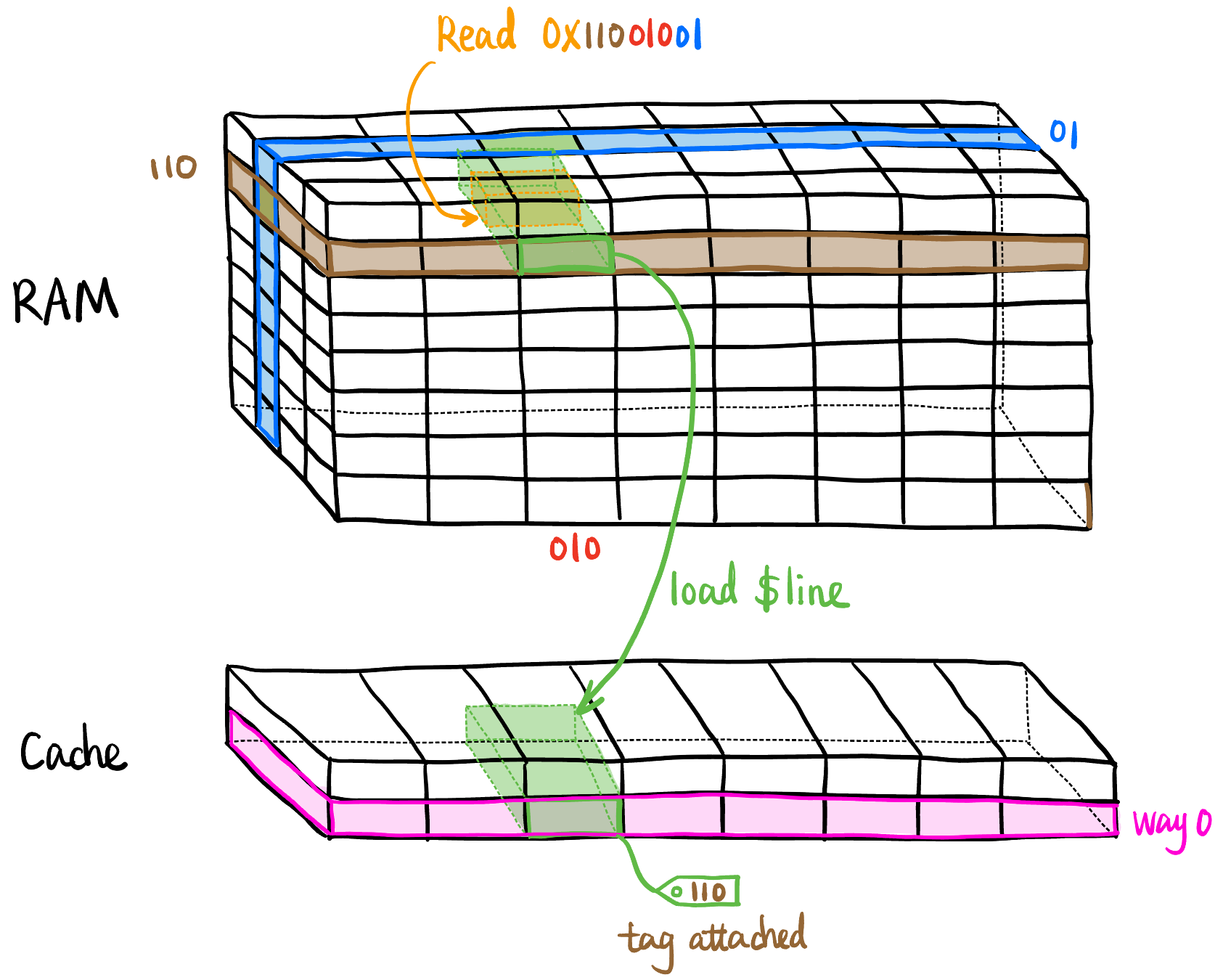
Cache 劫持 CPU 访存的地址, 在 CPU 和 memory 之间做完全透明的中间人.
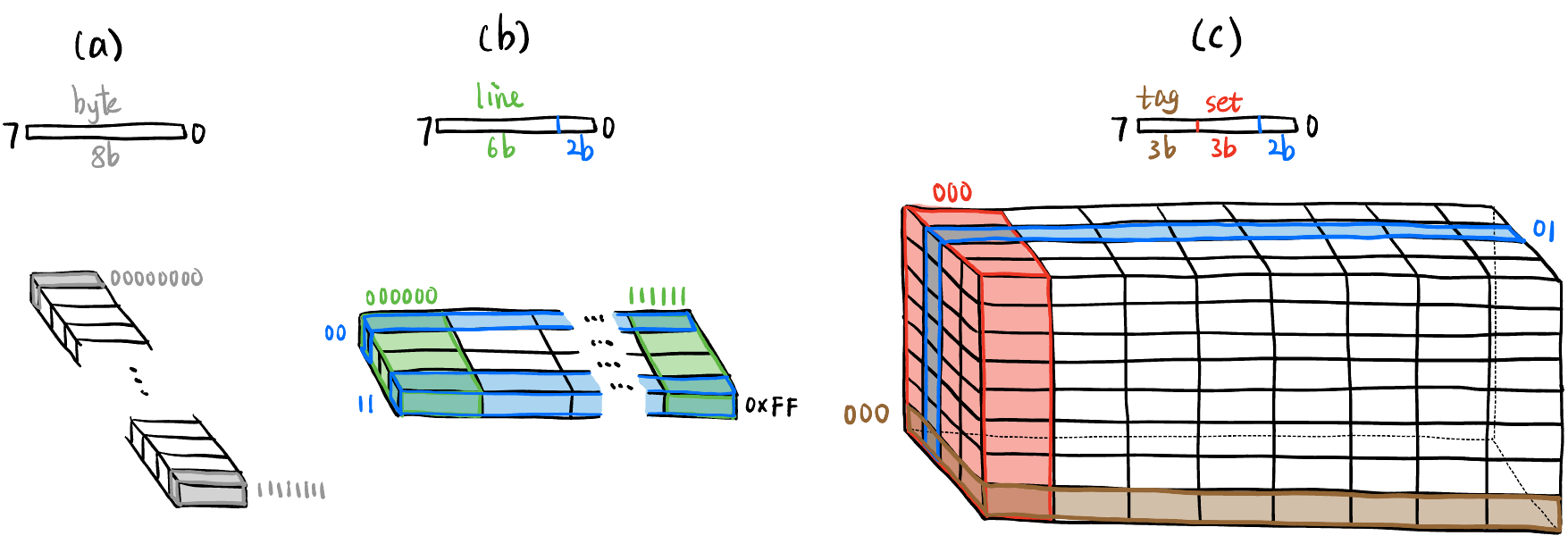
地址分段: 在网络中相当于子网划分, 在线性地址空间中相当于给数据加张量的结构 (但只是逻辑上的划分, 物理上地址还是线性的!).
- $Line: Cache 和 RAM 之间交换数据的最小单位.
- 注意不是一次加载 1B/1 word, 而是搬运请求地址附近的一整块数据, 因为内存附近的地址很可能马上用 (Spatial Locality), 一般是 64B (也有 32B, 128B 的), Figure fig-addr-partition 中是 4B.
- 有对齐操作! 不一定是从请求地址开始搬运, 如 Figure fig-addr-partition 是请求地址所在的 4B 对齐块开始搬运!
- $Set: 见 Figure fig-addr-partition (c).
- Fully Associative Cache: 没有 set 概念的 Cache (或者说只有 1 个 set).
- $Tag: 见 Figure fig-addr-partition (c).
- Way: 由于 Cache 容量有限 (即 Figure fig-cache-miss 中 Cache 的高度肯定小于 RAM 的高度), 在 Cache 中我们将 tag 附加在 $Line 里, 纵坐标起名为 way (Figure fig-cache-miss 中有 2 个 way).
- Direct-Mapped Cache: 只有 1 个 way 的 Cache.
- $Line: Cache 和 RAM 之间交换数据的最小单位.
Request Type: R/W.
Cache Miss/Hit: 请求 R/W 的数据地址不在/在 Cache 里.
- Cache Read Policy: Read 内存比较简单, 不会产生 Cache Coherence 问题. 在的话直接返回, 不在则需要从内存搬运数据到 Cache 里, 搬运过程见 Figure fig-cache-miss, 由 Cache controller 控制.
- Cache Write Policy: 多核处理器中写入某内存地址的时候, 要不要加载数据到 cache 以及要不要立即更新 RAM ().
- Write-Hit: 请求写入的地址在 Cache 里.
- Write-Through: 写入 Cache 的同时也写入 RAM.
- 这样数据一致性最好, 但是由于要写两边, 写入速度慢; 而且如果经常占用 memory bus 访问 RAM 的话会影响其它设备的访存效率.
- Write-Back: 先只写入 Cache, 当 block eviction 或 cash flush 时再写入 RAM.
- 这样可以多次写入 Cache 而只写一次写入 RAM, 提升写入效率、减少 memory bus 占用. 但是比较复杂, 需要引入 dirty bit 来标记某个 $Line 是否被修改过而且还没与 RAM 同步.
- Write-Through: 写入 Cache 的同时也写入 RAM.
- Write-Miss: 请求写入的地址不在 Cache 里.
- Write-Allocate: 先将要写的地址的 $Line 从 RAM 搬运到 Cache, 然后再写入 Cache. (后续是否要立即写入 RAM 取决于 Write-Hit 的策略, 但是一般是 Write-Back)
- No-Write-Allocate: 彻底绕过 cache, 直接写入 RAM. (一般配合 Write-Through 使用)
- Write-Hit: 请求写入的地址在 Cache 里.
Cache Replacement Algorithm: Cache Miss 时, 会找没有用过的 way 的相应 set 放数据. 如果都用过了, 则根据某种替换策略将某个 way 的数据换出去, 放入新数据. 下面是一些常见的算法的简化解释1:
- LRU (Least Recently Used): 将对应 set 中最少使用的 $Line 换出去. (最常用的算法)
- LFU (Least Frequently Used): 将对应 set 中使用频率最低的 $Line 换出去. (很少使用)
- Random Replacement: 随机选择某个 $Line 换出去. (用于访问模式不可预测或追求简单的场景)
- FIFO (First In First Out): 将对应 set 中最早进入的 $Line 换出去. (个人感觉没啥逻辑, 最早进来的数据不一定就不常用)
- MRU (Most Recently Used): 将对应 set 中最近使用的 $Line 换出去. (有点反直觉, 但适用于旧数据更容易被访问的场景)
- Adaptive Replacement: 将 set 分成 3 组, 前两组固定使用前面的两种算法, 第三组根据前两组的命中率动态调整使用哪种算法.
1 由于要让计算机知道哪些 $Line 最少使用/使用频率最低等等, 每个 $Line 都需要额外存储一些 metadata, 比如 LFU 中每个 $Line 上面不光有 tag 字段, 还有一个 frequency counter, 记录使用频率.
- Cache Hierarchy
- L1 Cache: 一般分为 Instruction Cache 和 Data Cache, 每个 core 独享. 但由于速度要求非常高, 容量很小 (16KB-128KB, 2-8 ways), 为了补偿容量小的问题, 我们引入:
- L2 Cache: 直接与核内的 L1 Cache 连接, Instruction 或 Data 都能存. (256KB-2MB, 4-16 ways)
- L3 Cache: 多核共享. (2MB-32MB, 16 ways)
- L4 Cache: L3 和 RAM 之间有时再加一层 L4 Cache.
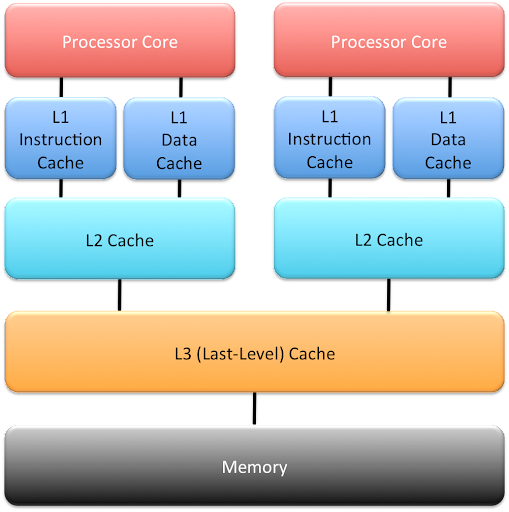
Figure 4: Cache Hierarchy. - Inclusion Policy: 相邻两级 cache 的数据 chunk 的包含关系, 分为:
- Inclusive: L1 的数据一定会在 L2 里, etc.
- Exclusive: L1 的数据一定不会在 L2 里, etc.
- NINE (Non-Inclusive Non-Exclusive): L1 的数据可能会也可能不会在 L2 里, etc.



Memory
内存: working memory, main memory
DRAM & SSD 内存与硬盘
- 读写速度 (3000 倍): 17 ns vs 50 ms, 超音速飞机和龟速
- 容量: 16GB vs 4TB
SIMM & DIMM
- DIMM (Dual In-line Memory Module)
Macros 宏
xlen = 32: Word length 字长, 即 GPR 寄存器宽度 (由于通用寄存器被命名为 x0~x31)